HBase在保证高性能的同时,为用户提供了便于理解的一致性数据模型,即多版本并发控制技术,把数据库的行锁与行的多个版本结合起来,从而去提高数据库系统的并发性能。
要理解mvcc,首先需知道为什么需要进行并发控制,我们知道关系型数据库一般都提供了跨越所有数据的ACID特性,为了性能考虑,HBase只提供了基于单行的ACID,维基上是这样介绍ACID的:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。

具体写入数据时是以KeyValue为数据单位的,对于上图中的数据来说,实际写入时有四个KeyValue,每个写入线程负责写入两个KeyValue,如果HBase没有相应的并发控制,则这四个KeyValue写入MemStore的顺序是无法预料的,可能会出现以下情况:

最终得到的结果是:

这样就得到了不一致的结果。显然我们需要对并发写操作进行同步。最简单的一种方案是在对某一行进行操作之前,首先显式对该行进行加锁操作,加锁成功后才进行相应操作,否则只能等待获取锁,此时,写入流程如下:
- (0) 获取行锁
- (1) 写WAL文件
- (2) 更新MemStore:将每个cell写入到memstore
- (3) 释放行锁
引入行锁的机制后,就可以避免并发情景下,对同一行数据进行操作(写入或更新)时出现数据交错的情况。
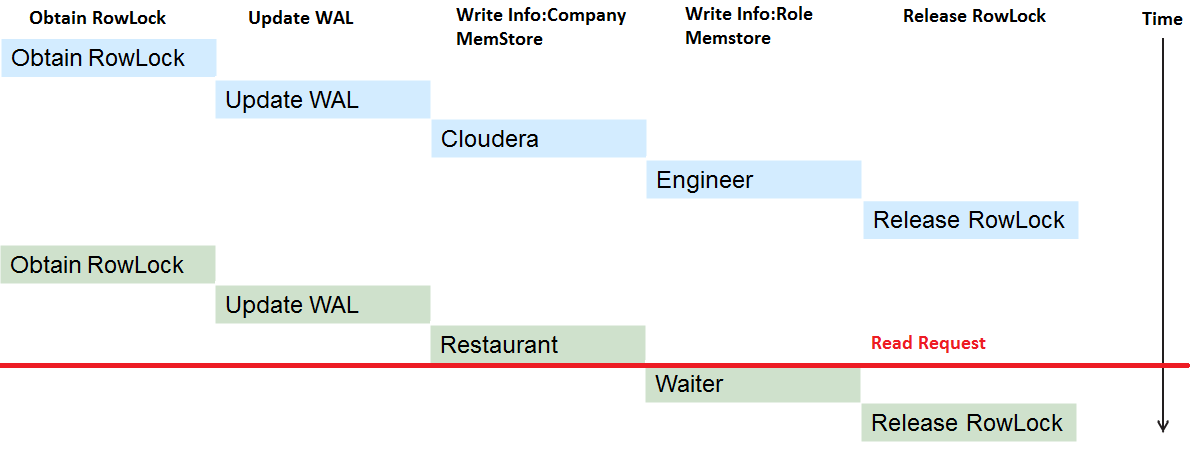

可见需要对读和写也进行并发控制,不然会得到不一致的数据。最简单的方案就是读和写公用一把锁。这样虽然保证了ACID特性,但是读写操作同时抢占锁会互相影响各自的性能。
最简单的方案是和写入一样,在读取操作前后分别加入获取锁与释放锁的步骤,这样的话,性能一下子就下来了。HBase使用了一种mvcc的策略来避免读取的锁操作。mvcc对于写操作:
- (w1) 获取行锁后,每个写操作都立即分配一个写序号
- (w2) 写操作在保存每个数据cell时都要带上写序号
- (w3) 写操作需要申明以这个写序号来完成本次写操作
对于读操作:
- (r1) 每个读操作开始都分配一个读序号,也称为读取点
- (r2) 读取点的值是所有的写操作完成序号中的最大整数(所有的写操作完成序号<=读取点)
- (r3) 对某个(row,column)的读取操作r来说,结果是满足写序号为“写序号<=读取点这个范围内”的最大整数的所有cell值的组合
使用了MVCC策略的执行过程如下:

采用MVCC后,每一次写操作都有一个写序号(即w1步),每个cell数据写memstore操作都有一个写序号(w2,例如:“Cloudera [wn=1]”)),并且每次写操作完成也是基于这个写序号(w3)。
如果在“Restaurant [wn=2]” 这步之后,“Waiter [wn=2]”这步之前,开始一个读操作。根据规则r1和r2,读的序号为1。根据规则3,读操作以序号1读到的值是:

这样就实现了以无锁的方式读取到一致的数据了。
总结:
引入MVCC后写入操作流程如下:
- (0) 获取行锁
- (0a) 获取写序号
- (1) 写WAL文件
- (2) 更新MemStore:将每个cell写入到memstore
- (2a) 以写序号完成操作
- (3) 释放行锁
参考英文:https://blogs.apache.org/hbase/tags/mvcc